当AI开始"斤斤计较":这家小公司凭什么让算力成本暴跌266倍?
你有没有过这样的经历?深夜对着ChatGPT问一个简单问题,然后盯着那个"正在思考"的转圈发呆,心里默默算着这次对话要花掉几毛钱电费。如果你做过企业级AI部署的预算,就会知道这个问题的答案可能让你倒吸一口凉气——推理成本往往是企业拥抱AI的第一道门槛。
但就在2026年春天,一家加拿大小公司带来了一个让人眼前一亮的消息:他们把AI推理的成本,砍到了原来的二百六十六分之一。
一个芯片老兵的"叛逆"之旅
故事要从LjubisaBajic说起。这位在AMD和英伟达都待过的架构师,做了一件让很多人看不懂的事:离开稳定的职位,拉着两个伙伴,创立了一家叫Taalas的公司。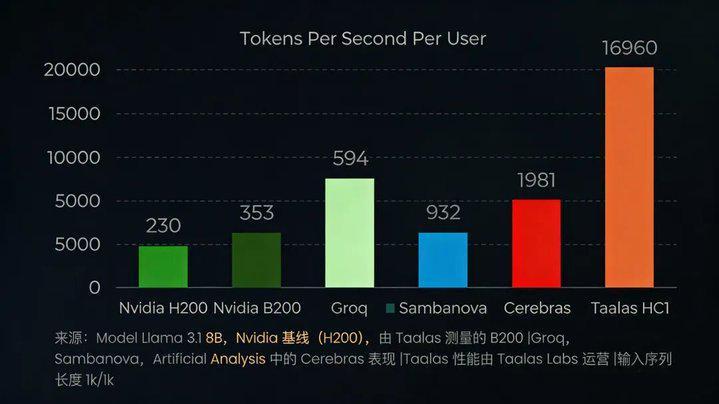
他的逻辑其实很朴素:现在的AI就像上世纪初的电力——珍贵、昂贵、只有大企业才能用得起。但如果想让AI真正像电一样走进千家万户,就必须把成本降下来,而且是大幅度地降。"1000倍的效率提升",这是他在公司成立时喊出的口号。
听起来很疯狂对吧?但投资人选择了相信他。皮埃尔·拉蒙德在领投5000万美元后说了一句很有意思的话:"他们做芯片的经验业内顶级,这个方向能实现1000倍的成本改善,推动AI成为基础设施级能力。"
不走寻常路的技术哲学
Taalas的做法跟市面上所有AI芯片都不一样。传统芯片的设计思路是"我这块芯片要能跑尽可能多的模型",所以要预留大量通用运算单元,要支持复杂的软件调度,要配备高带宽但昂贵的HBM内存。
Taalas的思路完全不同:既然推理时模型是固定的那为什么还要每次从内存里读取它?干脆把模型"焊"进芯片里算了。
于是就有了HC1芯片。它只支持一个模型(Llama3.18B),没有复杂的调度逻辑,不需要HBM。代价是牺牲了灵活性,但换来的效率提升是惊人的:17000Token每秒的推理速度,是英伟达H200GPU的50倍。
速度与精度的两难抉择
当然,新技术从来不是完美的。HC1的推理速度令人惊艳,但精度上还存在明显短板。简单运算偶尔会出错,复杂推理时偶尔会"一本正经地胡说八道"。
这不是设计失误,而是技术路线的取舍。要把模型固化在硅片上,就必须用定点数格式来存储权重,而定点数天然不如浮点数精确。Taalas的解决方案是:先用HC1占领市场,积累用户和数据,等技术更成熟后再推出精度更高的HC2。
中国科学院的一位研究员评价说:"虽然Taalas目前的状况还没有应用价值,但不妨碍它会成为一颗有历史意义的芯片。"这种"由先行者承担质疑成本"的桥段,在科技史上屡见不鲜。
谁会成为HC1的第一批用户?
答案藏在HC1的技术特性里。只需要想一想:什么样的场景最需要"快",同时又"不需要特别复杂"?
首先是企业智能客服。电商平台的AI客服每天要回答成千上万次重复问题,响应速度快一分,用户体验就好一分。HC1的"秒级响应"配合极低的单次调用成本,对于这类场景来说简直是量身定做。
其次是金融和医疗领域的私有化部署。这类行业对数据安全要求极高,必须在本地运行固定版本的模型。HC1的"一模型一芯片"设计,恰好完美匹配这种需求。
还有边缘设备。自动驾驶汽车、人形机器人、高端智能手机——这些设备需要在本地进行实时AI推理,不能依赖云端,但也不需要跑多模型。HC1的极低功耗和极高速度,让它成为边缘AI的有力候选。
这场芯片战争才刚刚开始
有意思的是,就在Taalas快速崛起的同时,行业老大英伟达也没闲着。2025年底,英伟达用200亿美元拿下了Groq的推理技术许可。这家同样做专用AI芯片的公司,跟Taalas走了类似的技术路线。
这说明什么?说明"效率优先"的推理芯片赛道,已经引起了顶级玩家的重视。未来的AI算力市场,很可能是通用芯片和专用芯片并存的时代:训练阶段用通用GPU,推理阶段根据场景选择专用芯片。
对于我们普通人来说,这场芯片战争的结果,最终会体现在AI应用的普及程度上。想象一下,如果AI推理的成本真的降到现在的二百六十六分之一,那么现在的很多"太贵了"的AI应用,都会变得值得尝试。
从"让AI像电力一样无处不在"的愿景来看,Taalas走了一条少有人走的路。路上有质疑、有挑战、有未知,但正是这种"不走寻常路"的勇气,才是技术进步的动力源泉。



